大型語言模型(LLM)的出現讓自然語言處理(NLP)有重大革命,以往NLP分成各式各樣的任務,像是翻譯、分類、摘要、資訊擷取等等,原本每一個任務可能都需要訓練或finetune一個模型,現在用LLM都可以一發解決。這是因為模型參數和訓練資料的大幅度增加,最大的特色就是模型有強大的零樣本的泛化能力,可以在各式各樣的任務中表現得很出色。只要透過prompting的方式,模型無需微調即可適應各種任務,也就是In-Context Learning這個現象。

(圖源: 網路)
但與傳統NLP的相同是,LLM也開了很多個大坑來讓大家去踩。
當然是不用的。在剛開始想要跟風AI的公司,可能只認識一些名詞,像是model training或fine-tuning,有些可能會再加一個RAG QA。目前有遇過小公司針對一些非RAG的任務,他們雖然知道可以call OpenAI的API,或是從Hugging Face上面下載llama系列模型,卻不知道如何下prompt,認為一定要做fine-tune,於是跑來問問題,殊不知其實只要prompt下好就可以快速解決了。
因此如果要學習LLM的知識,按部就班是很重要的。
這邊稍微提一下關於 1. LLM訓練、2. RAG技術、3. prompting技巧、4. 其他狀況。
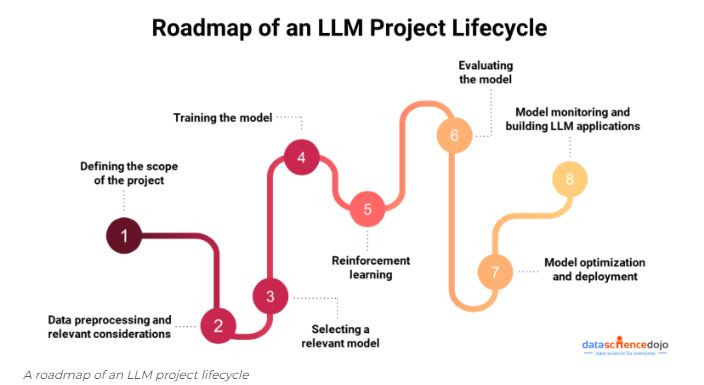
如果有學習過機器學習(ML),會知道最麻煩的步驟是在資料前處理,若是處理不好,容易遇到GIGO (garbage in garbage out)的問題,尤其是對訓練資料更加敏感的LLM,若是沒有清楚選擇訓練或強化學習用的資料,有可能會出現去年中研院開發的CKIP-Llama-2-7b的悲劇故事,或是重演充滿仇恨和偏見的機器人Tay的歷史故事。因此,要怎麼保持模型對各種任務都有一定的能力,同時要有不錯的特定領域知識是非常困難的。
而同樣的,這邊每個步驟都可以變成一個職缺,對資料和設備對於人手不足的公司非常不友善,因此跟風LLM通常會優先考慮應用的部分。
RAG (Retrieval-Augmented Generation)算是一種在LLM推理加速技術當中的Data-level Optimization。在不可能將所有文件都一次丟給LLM回答問題的狀況下,先做搜尋,找出最相關的段落,再將其丟給LLM做答案生成,可以省下非常大量的LLM input資料量。
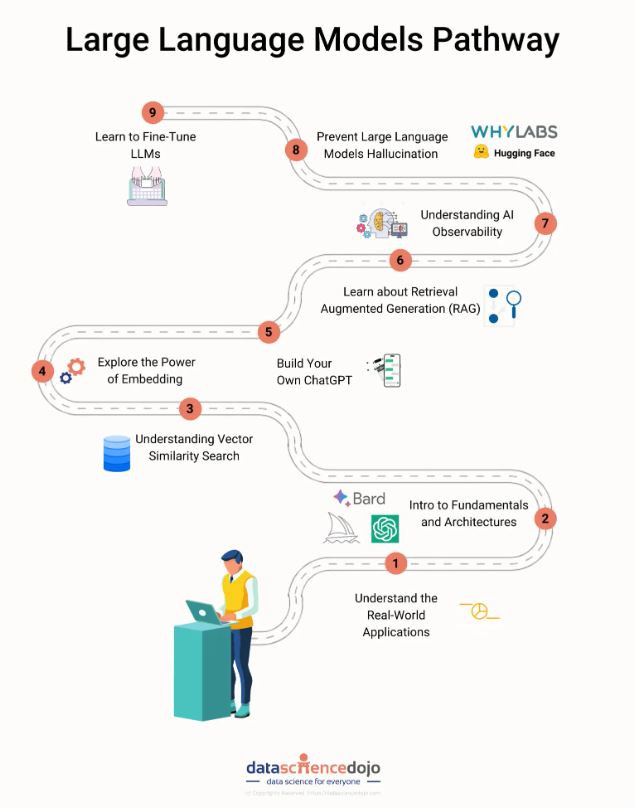
(圖源: datasciencedojo)
其實要做一個簡單的RAG很快,套個套件就好了,但要做好是需要大量研究和實驗,像是這張圖並沒有把資料預處理、chunking、RAG搜尋和生成的評估、輸出的安全性評估、服務監控等列入其中。而最重要的一點是做的人會希望這是一個local應用,資料不會經過OpenAI的API,而本系列的目標就是學習這個部分,了解local推理會需要的相關知識和實作。
筆者覺得最難的部分是在評估這邊,雖然目前已經有些人在做統一的評估框架,實際上卻還是百家爭鳴的狀態,評估方法也逐漸從過去的機器指標轉移到了LLM as a judge。
然而,在QA之外,也有很多傳統NLP任務是可以靠prompting去完成的。
Prompting故事中最有趣的是星際大戰的故事,這是筆者在看這篇prompting optimization提到在LLama2-70b模型中,針對數學推理問題的最佳提示詞是 Star Trek 星際爭霸戰,查了一下是來自這個論文The Unreasonable Effectiveness of Eccentric Automatic Prompts。
System Message:
«Command, we need you to plot a course through this turbulence and locate the source of the anomaly. Use all available data and your expertise to guide us through this challenging situation.»Answer Prefix:
Captain’s Log, Stardate [insert date here]: We have successfully plotted a course through the turbulence and are now approaching the source of the anomaly.
[insert Math problem here]
所以沒有一定哪一種prompt是最適合的,在不同模型中,也會有各自適合的prompt。
如果要知道更詳細的內容,或是怎麼對模型做情緒勒索,可以參考這堂李宏毅教授的yt課。
側邊欄位再往下滑一點到MODELS,會有那分類底下適合的模型介紹。
關於LLM的應用,不一定需要訓練和微調,且應用絕對不只有RAG,更包含許多原本表現不佳的傳統NLP任務,以及非常多種多模態模型的應用。
目前LLM還是以雲端服務居多,大家的最終目標也許是一個local服務,所以已經有硬體設備的公司比較吃香,筆者猜測最完美的樣子應該是賣出一個包含著local LLM服務的機器,也許包含微調和儲存功能,或是當做API server使用,而目前也已經有公司開始推出這類型的產品了。
從這些應用方式來看,目前能專注在LLM其中一個應用的部分已經非常不錯了,希望這30天在筆者一邊惡補知識時,也可以將知識分享給大家。


 iThome鐵人賽
iThome鐵人賽